前回
はじめに
前回はついに拡散モデルを実装して結果を確認しました。 VAEと比べて拡散モデルから生成した画像のほうがより鮮明でしたが、まだ不十分な点があります。 具体的には、前回までの拡散モデルでは生成される画像は完全にランダムで、自分が狙った画像を生成することができません。 そのため、今回はどのような画像を生成したいかについてもインプットして、狙った画像の生成を目的とした条件付きの拡散モデルを実装していきます。
STEP 10.1:条件付き拡散モデルのU-Net(デコーダー)の実装
すでに無条件の拡散モデルは前回実装したので、条件付き拡散モデルを実装するのはそこまで手間はかかりません。 まずはデコーダーであるU-Netのコードから手を加えていきましょう。条件付きを考えたいので、インプットされていた画像のラベル情報もデノイズする際に加えていきます。 Rコードは以下の通りです。追加した部分にコメントつけていますが、ここだけの追加でOKです。無条件のとき(ラベルがない場合)も出力できるようにIF文で条件付きかどうか判定しています。 IF文の条件が少し読みにくいですが、ただラベルの有無を確認しているだけになります。テンソルの扱いが少し慣れていないこともあり、少し冗長な形になっています。。
UNetCond <-nn_module( initialize =function(in_dim=1, time_embed_dim =100, num_labels=NA){ self$time_embed_dim = time_embed_dim self$down1 =ConvBlock(in_dim,64,time_embed_dim) self$down2 =ConvBlock(64,128,time_embed_dim) self$bot1 =ConvBlock(128,256,time_embed_dim) self$up2 =ConvBlock(128+256,128,time_embed_dim) self$up1 =ConvBlock(128+64,64,time_embed_dim) self$out =nn_conv2d(64,in_dim,1) self$maxpool =nn_max_pool2d(2) self$upsample =nn_upsample(scale_factor =2, mode ="bilinear")if(!is.na(num_labels)){ self$label_emb =nn_embedding(num_labels, time_embed_dim)}}, forward =function(x, timesteps, labels =NA){ v =pos_encoding(timesteps, self$time_embed_dim, x$device)#この部分がラベル情報を埋め込むためのコード(前回からの追加部分)if(labels %>%as.array()%>%is.na()%>%sum()%>%as.numeric()==0){ v = v + self$label_emb(labels)} x1 = self$down1(x,v) x = self$maxpool(x1) x2 = self$down2(x,v) x = self$maxpool(x2) x = self$bot1(x,v) x = self$upsample(x) x =torch_cat(c(x,x2),dim =2) x = self$up2(x,v) x = self$upsample(x) x =torch_cat(c(x,x1), dim =2) x = self$up1(x,v) x = self$out(x)return(x)})
STEP 10.2:条件付き拡散モデルの実装
次に最終段階の条件付き拡散モデルの実装に移ります。 Rコードは以下の通りで、追加や更新した部分にはコメント付けています。 特にmake_sample関数ではラベルの乱数を発生させていますが、1~10の整数を発生させています。 今回使用しているMNISTの数字は0~9ですが、内部で計算される際にそれぞれのラベルのインデックスが1から配番されるので、 数字が0の画像のインデックスは1となっているため、このように1つズレたようなコーディングとなっています。
DiffuserCond <-nn_module( initialize =function(num_timesteps=1000, betas_start=0.0001, beta_end=0.02, device ="cpu"){ self$num_timesteps = num_timesteps self$device = device self$betas =torch_linspace(betas_start,beta_end,num_timesteps,device = device) self$alphas =1- self$betas self$alpha_bars =torch_cumprod(self$alphas, dim=1)}, add_noise =function(x_0,t){ MAX_T =length(self$num_timesteps) alpha_bar = self$alpha_bars[t %>%as.array()] N = alpha_bar$size(1) alpha_bar = alpha_bar$view(c(N,1,1,1)) noise =torch_randn_like(x_0,device = self$device) x_t =torch_sqrt(alpha_bar)* x_0 +torch_sqrt(1- alpha_bar)* noise return(list(x_t,noise))}, denoise =function(model,x,t, labels){ MAX_T = self$num_timesteps alpha = self$alphas[t %>%as.array()] alpha_bar = self$alpha_bars[t %>%as.array()] alpha_bar_prev = self$alpha_bars[(t-1)%>%as.array()] N = alpha_bar$size(1) alpha = alpha$view(c(N,1,1,1)) alpha_bar = alpha_bar$view(c(N,1,1,1)) alpha_bar_prev = alpha_bar_prev$view(c(N,1,1,1)) model$eval()with_no_grad({ eps =model(x,t,labels)#ラベルもインプット model$train() noise =torch_randn_like(x, device = self$device) noise[t ==2]=0 mu =(x -((1-alpha)/torch_sqrt(1-alpha_bar))* eps)/torch_sqrt(alpha) std =torch_sqrt((1-alpha)*(1-alpha_bar_prev)/(1-alpha_bar))return(mu + noise * std)})}, reverse_to_img =function(x, iscolor =F){ tensor = x *255 tensor = tensor$clamp(0,255) tensor = tensor/255 tensor_array = tensor %>%as.array() tensor_dim =dim(tensor_array) color_dim =ifelse(iscolor,3,1) out =list()for(i in1:tensor_dim[1]){ tmp =array(NA,dim =c(tensor_dim[3],tensor_dim[4],1,color_dim)) tmp[,,1,1:color_dim]= tensor_array[i,1:color_dim,,] tmp[1:tensor_dim[3],,1,]= tensor_array[i,,1:tensor_dim[3],] tmp[,1:tensor_dim[4],1,]= tensor_array[i,,,1:tensor_dim[4]] out[[i]]=as.cimg(tmp)}return(out)},#ラベルをインプットする。 make_sample =function(model, x_shape =c(20,1,28,28), labels=NA){ batch_size = x_shape[1] x =torch_randn(x_shape, device = self$device)#ラベルの乱数を発生させる。if(labels %>%as.array()%>%is.na()%>%sum()%>%as.numeric()!=0){ labels =torch_randint(1,10,batch_size,device=self$device,dtype =torch_long())}for(i in self$num_timesteps:2){ t =torch_tensor(rep(i,batch_size), device = self$device, dtype =torch_long()) x = self$denoise(model, x, t, labels)}#ラベルも一緒に返すように更新return(list(x,labels))})
STEP 10.3:条件付き拡散モデルの学習&結果
では、上記で実装した条件付き拡散モデルを実際に学習して結果を確認してみましょう。 学習のためのRコードは以下の通りです。今回追加した部分にはコメント付けましたが、基本的にはラベルを追加したことを記載しています。
library(torchvision) img_size =28 batch_size =128 num_timesteps =1000 epochs =100 lr =10^-3 device =ifelse(cuda_is_available(),"cuda","cpu") ds <-mnist_dataset( root ="./data", train =TRUE,# default download =TRUE, transform =function(x){ y = x %>%transform_to_tensor()}) dl <-dataloader(ds, batch_size = batch_size, shuffle =TRUE) diffuser =DiffuserCond(num_timesteps,device = device) model =UNetCond(num_labels=10)#ラベルの種類数をインプット optimizer =optim_adam(model$parameters, lr=lr) losses =c()for(epoch in1:epochs){ loss_sum =0.0 cnt =0 coro::loop(for(img in dl){ optimizer$zero_grad() x = img$x y = img$y #今回はラベルも必要 shape = x$shape t =torch_randint(1, num_timesteps,shape[1],device = device) x_noisy = diffuser$add_noise(x,t) noise_pred =model(x_noisy[[1]],t, y)#インプットにラベルを追加 loss =nnf_mse_loss(x_noisy[[2]],noise_pred,reduction ="sum") loss$backward() optimizer$step() loss_sum = loss_sum + loss$item() cnt = cnt +1}) loss_avg = loss_sum / cnt losses =c(losses, loss_avg)cat("Epoch: ",epoch,"| Loss: ", loss_avg)}
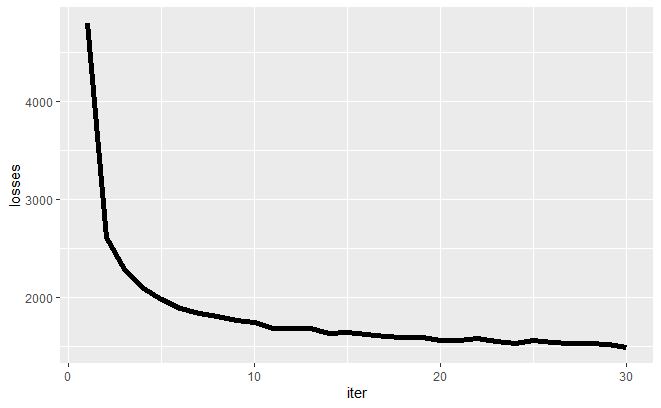
今回はエポック数を30程度で止めておきました。損失関数の推移を見る限りいい感じに学習はできてそうです。 次にちゃんとインプットしたラベル情報に沿った画像が生成されているかを確認してみましょう。以下のRコードで結果を図示できます。
tmp = diffuser$make_sample(model = model, x_shape =c(10,1,28,28)) gen_img = diffuser$reverse_to_img(tmp)par(mfrow=c(2,5))par(oma =c(1,1,1,1))for(i in1:10){plot(gen_img[[i]]%>%mirror(axis ="x")%>%rotate_xy(-90,14,14), axes =FALSE, main =paste("label =",(tmp[[2]][i]-1)%>%as.numeric()))}

ラベルと画像の内容がほぼ一致していることがわかるかと思います。 このようにラベル情報を付与するだけで狙った画像を得ることができるモデルを作成することができました。
まとめ
今回は条件付き拡散モデルの実装を行いました。まだまだ改良点は多いものの、これも立派な生成モデルと言えるかと思います。 次回は同じく条件付き拡散モデルではあるのですが、その学習方法をより洗練するための「ガイダンス」について触れ、実装していきたいと思います。