前回
はじめに
前回はVAEを実装してMNISTの数字の画像の生成をしてみました。私の手元で学習したVAEだと少しボヤっとした画像でしたが、数字であることはわかる程度の精度で生成できました。 今回は拡散モデルを実装しておなじように画像の生成を行います。参考書の第八章は拡散モデルの理論についてわかりやすく説明しています。今回のメインの目的は拡散モデルのRコードの実装であり、拡散モデル自体の理論の説明ではありません。 そのため、第八章は大幅に割愛したいと思います。その第八章の結論部分と第九章の実装部分を参照しながら、Rコードを作成していきます。
Rとpythonでは画像の扱い方が異なったりインデックスが0開始と1開始で異なったりと、元のpythonコードと異なる点がいくつかあります。 ちなみに、今回お見せする結果はCPUで推定したモデルですが、私の環境でGPUを使用するとsession aborted fatal errorとなり強制終了となってしまいました。 また、お見せしているコードのdevice部分をcpuからcudaに変えるとUNet部分でCPUとGPUが混ざってしまうため、session aborted fatal errorとならない、かつCPUとGPUが混ざらないように色々と試行錯誤してみたのですが、まだうまくいっていません。 ここら辺がうまくいったら本稿のコードを更新したいと思っていますが、ご覧になった方で直すべきポイントがわかる方がいらっしゃいましたらコメントいただけますと幸いです。。
STEP 7.1:拡散モデルについて
前回のVAEでは、元の画像を潜在変数へと変換するエンコーダーと、潜在変数を元の画像に戻すデコーダーの2種類のモデルがくっ付いたモデルとなっていました。 そのため、潜在変数を適当に生成してデコーダーにインプットすれば、学習に使用した画像の特徴を持つ画像が生成できます。
一方、拡散モデルは元の画像にノイズを徐々に加えていき、最終的にはノイズしかない状態までもっていきます(VAEで言うとエンコーダー部分に近い)。 そして、そのノイズが含まれた画像から徐々にノイズを取り除くことで元の画像に戻していき、最終的にノイズを消して画像を取り出すというモデルです(こちらはデコーダー部分)。 そのため、モデルを学習した後、ノイズ(乱数)を発生させて拡散モデルのデコーダーにインプットすれば、徐々にそのノイズから画像が生成されていく、ということになります。
ちなみに、この技術を活用したモデルにStable Diffusionがありますが、Stable Diffusionの大枠は以下の通りです。
画像をVAEのエンコーダーに通して潜在変数へ変換する。
潜在変数を拡散モデルのエンコーダーに通してノイズを加える。
ノイズが加わった潜在変数をUNetでデノイズ(ノイズ除去)する。
デノイズされた潜在変数をVAEのデコーダーに通して元の画像に変換する。
基本は上記の流れで画像が生成されますが、Stable Diffusionではここにテキスト情報を追加することで、そのテキストに沿った画像を生成できるように工夫されています。 簡単なStable Diffusionの説明は以上ですが、ここで言いたいことは、今まで実装してきたVAEと今回実装する拡散モデルを学習することで、あの有名なStable Diffusionの根本に触れることができるということです。 もちろん、公表されているモデルは他の工夫点が沢山盛り込まれていると思いますが、基本を押さえることはとても重要なので見ていきましょう。
STEP 7.2:拡散モデルの拡散過程(エンコーダー)の実装
まずは拡散モデルのエンコーダーとも呼べる拡散過程の実装を行っていきます。 拡散過程は簡単に言うと画像にノイズを加えていくモデルで、数式で表すと以下のようになります。
ここでは
回ノイズが加えれた画像データだと思ってください。ざっくり言うと、
回ノイズが加えられた画像
を中心として、その画像に少しガウスノイズを加えたものが
となります。
また、
は自前で決めるパラメータになっており、どのくらいのスピードでノイズを加えていくかを決定するものになります。
この値が大きいと加えるノイズの量が大きくなるため早く元の画像がノイズだらけになりますが学習がうまくいかなくなる可能性が高まります。一方、小さすぎても学習に時間がかかりすぎてしまうのでバランスが重要です。
その値の決め方は色々提案されていますが、今回は拡散モデルの原論文にそって0.0001から0.02まで線形に変化する方法を取りたいと思います。
では、ここまで実装してみます。今回使用する画像はWebから適当にとってきた以下の画像(Stable Diffusionから生成された画像)です。 こちらの画像にノイズを徐々に加えていきます。ちなみに、コード中に「cimg2tensor」とありますが、これは自前の関数でimagerパッケージでロードした画像をtorchパッケージで使用するテンソルへ変換するものです。 もっと良いやり方があるのかもしれませんが、Rの画像系パッケージとtorchパッケージの相性は左程良くなく、少し次元の整理をしなくてはならないので手間ですね。。

library(imager) cimg2tensor =function(img, iscolor =T){ img_array = img %>%as.array() img_dim =dim(img_array) color_dim =ifelse(iscolor,3,1) tmp =array(NA,dim =c(img_dim[1],img_dim[2],color_dim)) tmp[,,1:color_dim]= img_array[,,1,1:color_dim] tmp[1:img_dim[1],,]= img_array[1:img_dim[1],,1,] tmp[,1:img_dim[2],]= img_array[,1:img_dim[2],1,] out =torch_tensor(tmp)return(out)} img =load.image("./data/image.png") x =cimg2tensor(img) MAX_T =1000 betas =torch_linspace(0.0001,0.02, MAX_T) plot_list =list() plot_num =1for(t in1:MAX_T){if(t %%100==0){ img =tensor2cimg(x) plot_list[[plot_num]]= img plot_num = plot_num +1} beta = betas[t] eps =torch_randn_like(x) x =torch_sqrt(1-beta)* x +torch_sqrt(beta)* eps }#描写par(mfrow=c(2,5))par(oma =c(1,1,1,1))for(i in1:10){ plot_list[[i]]%>%plot(axes =FALSE, main =paste("t =", i*100))}

このように元の画像にノイズを加えていくことで、最終的にはノイズだけになる様子が見て取れるかと思います。
しかし、モデルの学習のためには大量の画像データが必要であり、その画像1つ1つに上記のように徐々にノイズを加えていく方法だと学習時間が大変なことになってしまいます。
そこで、加えているノイズがガウスノイズであることに注目すると、正規分布+正規分布=正規分布という正規分布の再生性の性質を上手く利用できそうです。
その性質を活用すると元の画像からノイズを
回加えた画像
へ一気に飛ぶことができます。数式で書くと以下の通りです。
これを実装すると以下のようになります。また、冒頭の「tensor2cimg」はtorchパッケージのテンソルからimagerパッケージの画像形式へ変換する自前の関数です。 そのため、拡散モデルには関係ないところなので飛ばしていただいて大丈夫です(急にコード内に出てきたらtorchパッケージの関数だと誤解される可能性があると思い載せています)。
tensor2cimg =function(tensor, iscolor =T){ tensor = tensor *255 tensor = tensor$clamp(0,255) tensor = tensor/255 tensor_array = tensor %>%as.array() tensor_dim =dim(tensor_array) color_dim =ifelse(iscolor,3,1) tmp =array(NA,dim =c(tensor_dim[1],tensor_dim[2],1,color_dim)) tmp[,,1,1:color_dim]= tensor_array[,,1:color_dim] tmp[1:tensor_dim[1],,1,]= tensor_array[1:tensor_dim[1],,] tmp[,1:tensor_dim[2],1,]= tensor_array[,1:tensor_dim[2],] out =as.cimg(tmp)return(out)} beta_start =0.0001 beta_end =0.02 MAX_T =1000 betas =torch_linspace(beta_start,beta_end,MAX_T) add_noise =function(x_0,t,betas){ MAX_T =length(betas)if(!(t>=1& t<=MAX_T)){stop("ERROR\n")}else{ alphas =1- betas alpha_bars =torch_cumprod(alphas, dim =1) alpha_bar = alpha_bars[t] eps =torch_randn_like(x_0) x_t =torch_sqrt(alpha_bar)* x_0 +torch_sqrt(1- alpha_bar)* eps }return(x_t)} img =load.image("./data/image.png") x =cimg2tensor(img) x =add_noise(x,100,betas) img_add_noise =tensor2cimg(x)plot(img_add_noise, axes =FALSE)

画像を見る限りうまくいってそうですね。これでエンコーダー部分の実装は完了です。
STEP 7.3:拡散モデルのU-Net(デコーダー)の実装
拡散モデルのデコーダーにはU-Netが使用されることが多いみたいです。他にもSelf-AttentionやTransformerなども考えられているようですが、使用する画像の複雑さなどから使用するモデルを選択すればよいかと思います。 今回の学習ではMNISTの数字画像のデータを使用するので、U-Netでも十分な性能がある判断してその実装を進めていきます。U-Netに関する細かい説明はWebや原論文など至る所に転がっているので大部分は割愛し、簡単な説明のみ記載します。
U-Netは以下の画像のような構造を持つモデルで、モデルの構造が画像の通りU字であることからU-Netという名前がついているようです。 内容としてはそこまで複雑ではなくCNNを繰り返すのですが、一番の特徴はスキップ接続であり、モデル構造における縮小ステージと拡大ステージの間で情報を直接伝える機構がついています。 これにより、画像全体の特徴と細かい部分の特徴を合わせて処理を行うことが可能になります。

また、上記で実装した通り、拡散モデルでは拡散過程を通して回ノイズを加えた画像を使用して学習をしていきます。
そのため、U-Netにインプットした画像が何回ノイズを加えた画像なのかを知らせる必要があります。これは時系列系のモデルでもよく使用されている正弦波位置エンコーディングを使用します。
以上のことをまとめると、拡散モデルのデコーダーにはU-Netを使用し、そのインプットは回ノイズを加えた画像
と、その画像が何回ノイズを加えたものなのかを知らせる変数
となります。
これらのことを実装すると以下のようになります。
#正弦波位置エンコーディングの実装 pos_encoding_t =function(t, out_dim, device ="cpu"){ D = out_dim v =torch_zeros(D, device = device) i =torch_arange(0,D,device = device) div_term =10000**(i/D) v[seq(2,D,2)]=torch_sin(t / div_term[seq(2,D,2)]) v[seq(1,D,2)]=torch_cos(t / div_term[seq(1,D,2)])return(v)} pos_encoding =function(ts, out_dim, device ="cpu"){ batch_size =length(ts) v =torch_zeros(batch_size, out_dim, device = device)for(i in1:batch_size){ v[i]=pos_encoding_t(ts[i], out_dim, device)}return(v)}#U-Netで使用する画像処理ブロック(内容としてはCNNと正弦波位置エンコーディングの組み合わせ) ConvBlock <-nn_module( initialize =function(in_dim,out_dim,time_embed_dim){ self$conv =nn_sequential(nn_conv2d(in_dim,out_dim,3,padding =1),nn_batch_norm2d(out_dim),nn_relu(),nn_conv2d(out_dim,out_dim,3,padding =1),nn_batch_norm2d(out_dim),nn_relu()) self$mlp =nn_sequential(nn_linear(time_embed_dim, in_dim),nn_relu(),nn_linear(in_dim,in_dim))}, forward =function(x,v){ shape = x$shape v = self$mlp(v) v = v$reshape(c(shape[1], shape[2],1,1))return(self$conv(x+v))})#U-Netの実装 UNet <-nn_module( initialize =function(in_dim=1, time_embed_dim =100){ self$time_embed_dim = time_embed_dim self$down1 =ConvBlock(in_dim,64,time_embed_dim) self$down2 =ConvBlock(64,128,time_embed_dim) self$bot1 =ConvBlock(128,256,time_embed_dim) self$up2 =ConvBlock(128+256,128,time_embed_dim) self$up1 =ConvBlock(128+64,64,time_embed_dim) self$out =nn_conv2d(64,in_dim,1) self$maxpool =nn_max_pool2d(2) self$upsample =nn_upsample(scale_factor =2, mode ="bilinear")}, forward =function(x, timesteps){ v =pos_encoding(timesteps, self$time_embed_dim, x$device) x1 = self$down1(x,v) x = self$maxpool(x1) x2 = self$down2(x,v) x = self$maxpool(x2) x = self$bot1(x,v) x = self$upsample(x) x =torch_cat(c(x,x2),dim =2) x = self$up2(x,v) x = self$upsample(x) x =torch_cat(c(x,x1), dim =2) x = self$up1(x,v) x = self$out(x)return(x)})
STEP 7.4:拡散モデルの実装
では、今まで紹介した内容を整理して拡散モデルを実装していきます。 以下のコードでは、上記に記載した画像にノイズを加える機構とU-Netでデノイズする機構を入れています。 また、学習後に画像を生成する機構とその生成した画像をimagerパッケージの形式に沿った画像に変換する機構も併せて実装しています。
Diffuser <-nn_module( initialize =function(num_timesteps=1000, betas_start=0.0001, beta_end=0.02, device ="cpu"){ self$num_timesteps = num_timesteps self$device = device self$betas =torch_linspace(betas_start,beta_end,num_timesteps,device = device) self$alphas =1- self$betas self$alpha_bars =torch_cumprod(self$alphas, dim=1)}, add_noise =function(x_0,t){ MAX_T =length(self$num_timesteps) alpha_bar = self$alpha_bars[t %>%as.array()] N = alpha_bar$size(1) alpha_bar = alpha_bar$view(c(N,1,1,1)) noise =torch_randn_like(x_0,device = self$device) x_t =torch_sqrt(alpha_bar)* x_0 +torch_sqrt(1- alpha_bar)* noise return(list(x_t,noise))}, denoise =function(model,x,t){ MAX_T = self$num_timesteps alpha = self$alphas[t %>%as.array()] alpha_bar = self$alpha_bars[t %>%as.array()] alpha_bar_prev = self$alpha_bars[(t-1)%>%as.array()] N = alpha_bar$size(1) alpha = alpha$view(c(N,1,1,1)) alpha_bar = alpha_bar$view(c(N,1,1,1)) alpha_bar_prev = alpha_bar_prev$view(c(N,1,1,1)) model$eval()with_no_grad({ eps =model(x,t) model$train() noise =torch_randn_like(x, device = self$device) noise[t ==2]=0 mu =(x -((1-alpha)/torch_sqrt(1-alpha_bar))* eps)/torch_sqrt(alpha) std =torch_sqrt((1-alpha)*(1-alpha_bar_prev)/(1-alpha_bar))return(mu + noise * std)})}, reverse_to_img =function(x, iscolor =F){ tensor = x *255 tensor = tensor$clamp(0,255) tensor = tensor/255 tensor_array = tensor %>%as.array() tensor_dim =dim(tensor_array) color_dim =ifelse(iscolor,3,1) out =list()for(i in1:tensor_dim[1]){ tmp =array(NA,dim =c(tensor_dim[3],tensor_dim[4],1,color_dim)) tmp[,,1,1:color_dim]= tensor_array[i,1:color_dim,,] tmp[1:tensor_dim[3],,1,]= tensor_array[i,,1:tensor_dim[3],] tmp[,1:tensor_dim[4],1,]= tensor_array[i,,,1:tensor_dim[4]] out[[i]]=as.cimg(tmp)}return(out)}, make_sample =function(model, x_shape =c(20,1,28,28)){ batch_size = x_shape[1] x =torch_randn(x_shape, device = self$device)for(i in self$num_timesteps:2){ t =torch_tensor(rep(i,batch_size), device = self$device, dtype =torch_long()) x = diffuser$denoise(model, x, t)}return(x)})
これで拡散モデルを実装することができましたので、実際に学習していきます。 学習に使用するデータはtorchvisionパッケージからMNISTの数字画像データを取ってきます。 CPUで学習するにはかなり時間がかかるのでご注意ください。私はepochを80回程度で止めてしまいましたが、10時間以上かかってしまいました。 (参考書にもCPUだと1epochごとに10分程度かかると記載があります。)
library(torchvision) img_size =28 batch_size =128 num_timesteps =1000 epochs =100 lr =10^-3 device =ifelse(cuda_is_available(),"cuda","cpu") ds <-mnist_dataset( root ="./data", train =TRUE,# default download =TRUE, transform =function(x){ y = x %>%transform_to_tensor()}) dl <-dataloader(ds, batch_size = batch_size, shuffle =TRUE) diffuser =Diffuser(num_timesteps,device = device) model =UNet() optimizer =optim_adam(model$parameters, lr=lr) losses =c()for(epoch in1:epochs){ loss_sum =0.0 cnt =0 coro::loop(for(img in dl){ optimizer$zero_grad() x = img$x shape = x$shape t =torch_randint(1, num_timesteps,shape[1],device = device) x_noisy = diffuser$add_noise(x,t) noise_pred =model(x_noisy[[1]],t) loss =nnf_mse_loss(x_noisy[[2]],noise_pred,reduction ="sum") loss$backward() optimizer$step() loss_sum = loss_sum + loss$item() cnt = cnt +1}) loss_avg = loss_sum / cnt losses =c(losses, loss_avg)cat("Epoch: ",epoch,"| Loss: ", loss_avg)}
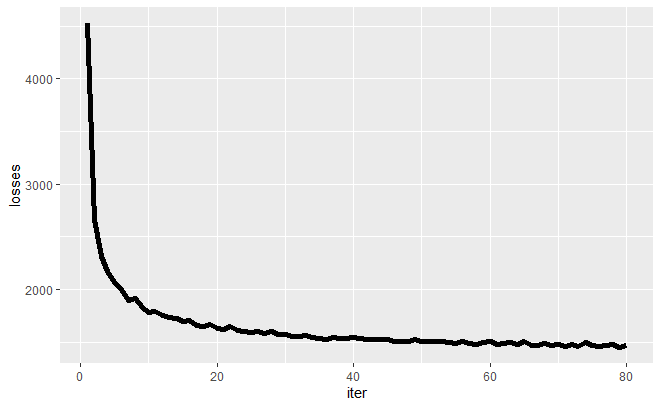
こちらのコードで学習した結果を示していきたいと思います。 まずは損失関数の推移ですが、以下の通りでした。順調に値が減っていることがわかるかと思います。 今回は80epochくらい回しましたが、半分の40epochくらいでも十分に損失が減っているので学習時間はもっと減らせそうですね。
次に、学習したモデルから画像を生成してみたいと思います。 Rコードは以下の通りです。最後のplot部分で画像の細かい位置調整をしていますが、ここら辺はもう少しうまく実装すればこのような調整は不要かもしれません。。
tmp = diffuser$make_sample(model = model, x_shape =c(10,1,28,28)) gen_img = diffuser$reverse_to_img(tmp[[10]])par(mfrow=c(2,5))par(oma =c(1,1,1,1))for(i in1:10){plot(gen_img[[i]]%>%mirror(axis ="x")%>%rotate_xy(-90,14,14), axes =FALSE)}
このコードで生成した画像は以下の通りです。 少し怪しい画像もありますが、VAEの時と比べて鮮明に数字とわかる画像が生成されているように思えます。 学習に時間を要しましたが、うまい具合に画像が生成できてよかったです。。

まとめ
今回は拡散モデルの実装を行いました。前回までと比べてかなり複雑化してきたので、コードも長くなってきました。 一番痛いところはやはりGPU計算の試行がうまくいっていないことですね。。これがうまくいけばトライ&エラーをもっと高速に回せるので、いつかちゃんと要因をとらえて修正していきたいと思っています。 ここら辺詳しい方はコメントいただけると大変うれしいです。。